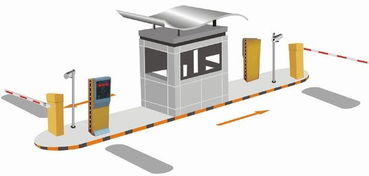
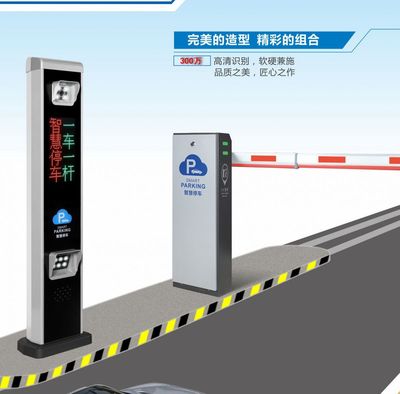
隨著城市化進程的加速和汽車保有量的激增,高效、便捷、安全的停車管理已成為社區、商業綜合體乃至整個城市運營的迫切需求。一套集成了智能收費、小區車牌識別、車場道閘控制等核心功能的停車場管理系統,正成為解決“停車難”問題的關鍵利器。而專業、可靠的“北京上門安裝”服務,則是確保這套復雜系統平穩落地、高效運行的最后一塊拼圖。
核心模塊解析:構建智能停車生態
一個完整的智能停車場管理系統,絕非單一設備的堆砌,而是一個由多個子系統協同工作的有機整體。
1. 智能車牌識別系統:出入無感,體驗升級
這是系統的“眼睛”和“大腦”。通過部署在出入口的高清攝像頭和先進的識別算法,系統能在瞬間完成對車輛牌照的抓拍、識別與比對。對于已授權的固定車輛(如小區住戶),可實現無需停頓的“無感通行”,極大提升通行效率與用戶體驗;對于臨時車輛,則自動記錄入場時間,為精準計費奠定基礎。
2. 高速道閘控制系統:安全可靠的物理屏障
作為系統的“手臂”,道閘是管理車輛通行的關鍵執行部件。與車牌識別系統聯動,在識別合法車輛后自動抬桿放行。具備防砸車功能(如地感線圈、紅外對射等),確保通行安全。快速平穩的啟閉,也減少了車輛等待時間。
3. 智能收費管理系統:靈活透明,杜絕糾紛
這是系統的“管家”。支持多種計費模式(如臨時計費、月卡、季卡、VIP套餐等),并可通過中央管理系統靈活設置費率。支付方式高度多樣化,支持現金、掃碼支付(微信/支付寶)、無感支付、ETC等,滿足不同車主需求。所有收費記錄清晰可查,賬目一目了然,有效規范管理、防止漏洞。
4. 中央管理平臺與數據看板:全局掌控,智慧決策
云端或本地的管理平臺是系統的“指揮中心”。管理人員可以遠程監控各個車場的實時狀態(車位數量、道閘開合、車輛進出記錄)、處理異常、管理用戶與權限、生成豐富的財務報表和運營分析圖表。這些數據為車場規劃、定價策略調整、高峰期疏導提供了科學依據。
“北京上門安裝”服務的核心價值
在技術方案成熟的前提下,專業的安裝與調試是決定系統成敗的關鍵。選擇提供“北京上門安裝”服務的供應商,具有不可替代的優勢:
- 現場勘察與定制化設計: 工程師上門實地測量,根據出入口環境、車流量、道路條件等因素,量身定制設備安裝位置、布線方案及網絡部署計劃,確保方案最優。
- 標準化規范施工: 嚴格按照行業標準進行設備安裝、線路敷設與防護,保證硬件穩固、信號穩定、用電安全,為系統長期穩定運行打下堅實基礎。
- 系統聯調與功能測試: 完成硬件安裝后,進行全面的系統聯動調試,確保車牌識別、道閘起降、計費邏輯、數據上傳等各個環節無縫銜接,功能完整實現。
- 人員培訓與售后保障: 對物業或車場管理人員進行操作與日常維護培訓,并提供及時的技術支持與售后服務網絡,解決后續使用中的任何問題,讓用戶無后顧之憂。
應用場景與深遠影響
此類系統不僅適用于住宅小區,還廣泛應用于寫字樓、商場、醫院、景區、公共停車場等場景。其帶來的效益是多方位的:
- 對車主而言: 享受快速通行、多種支付方式的便利,節省時間,提升滿意度。
- 對物業管理方而言: 大幅降低人工成本,提高管理效率和收費透明度,增加停車收入,同時借助數據提升整體服務品質和資產價值。
- 對城市管理而言: 有助于緩解交通擁堵,規范停車秩序,為智慧城市構建重要的數據節點。
###
整合了智能收費、車牌識別與道閘控制的全套停車場管理系統,配合專業的“北京上門安裝”服務,正在重新定義停車管理的標準。它不僅僅是一套硬件和軟件的集合,更是一種提升運營效率、優化用戶體驗、實現資產增值的綜合性解決方案。投資這樣一套系統,意味著選擇了自動化、數字化與智能化的未來管理之路,為應對日益嚴峻的停車挑戰提供了堅實可靠的智慧答案。